背景
通过grafana发现,K8S集群节点利用率存在突刺的情况,具体如下图所示:
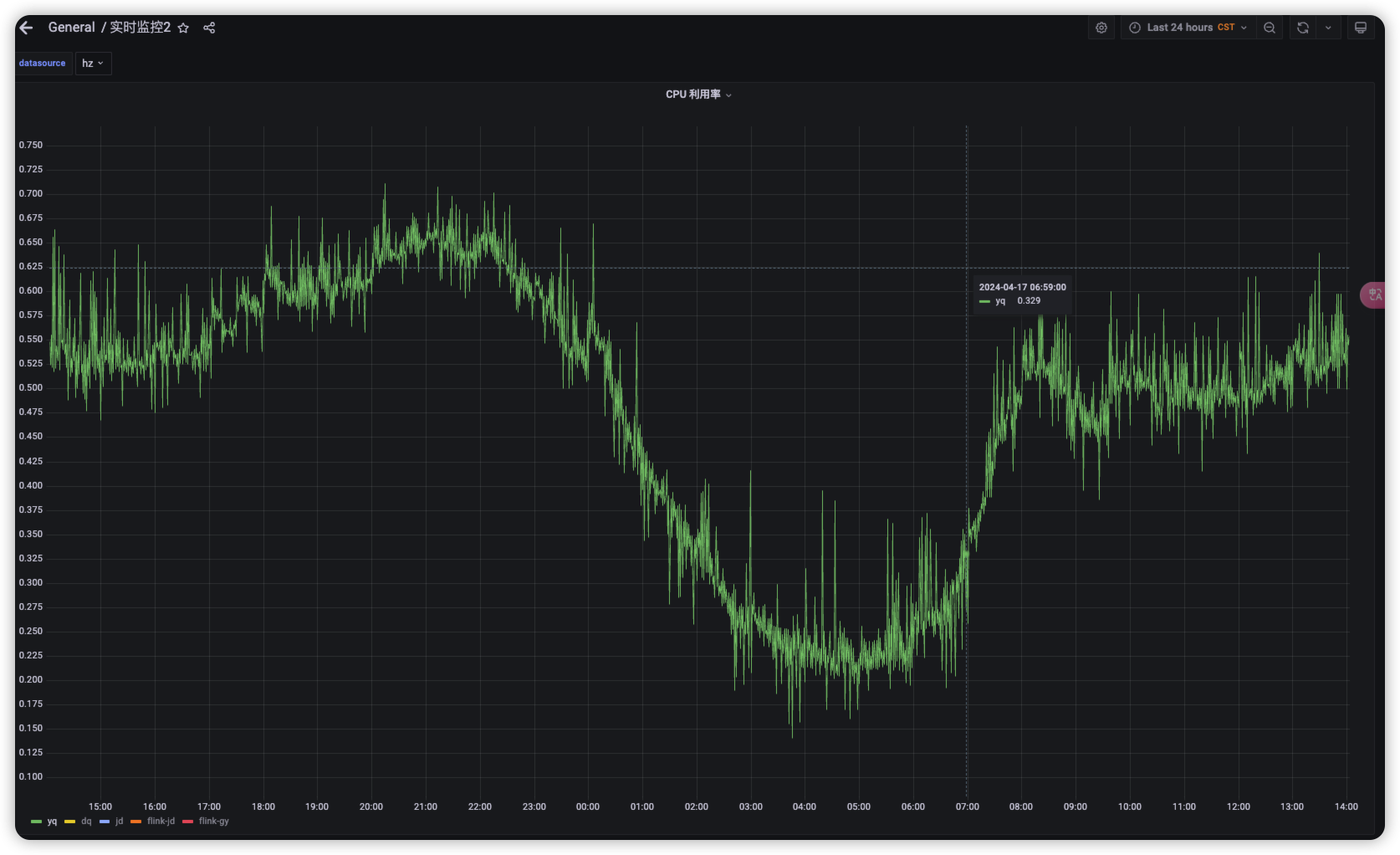
现象:
- 波动很大,有突然下落到很低利用率的情况
监控数据
表达式说明
CPU 利用率 看板计算表达式
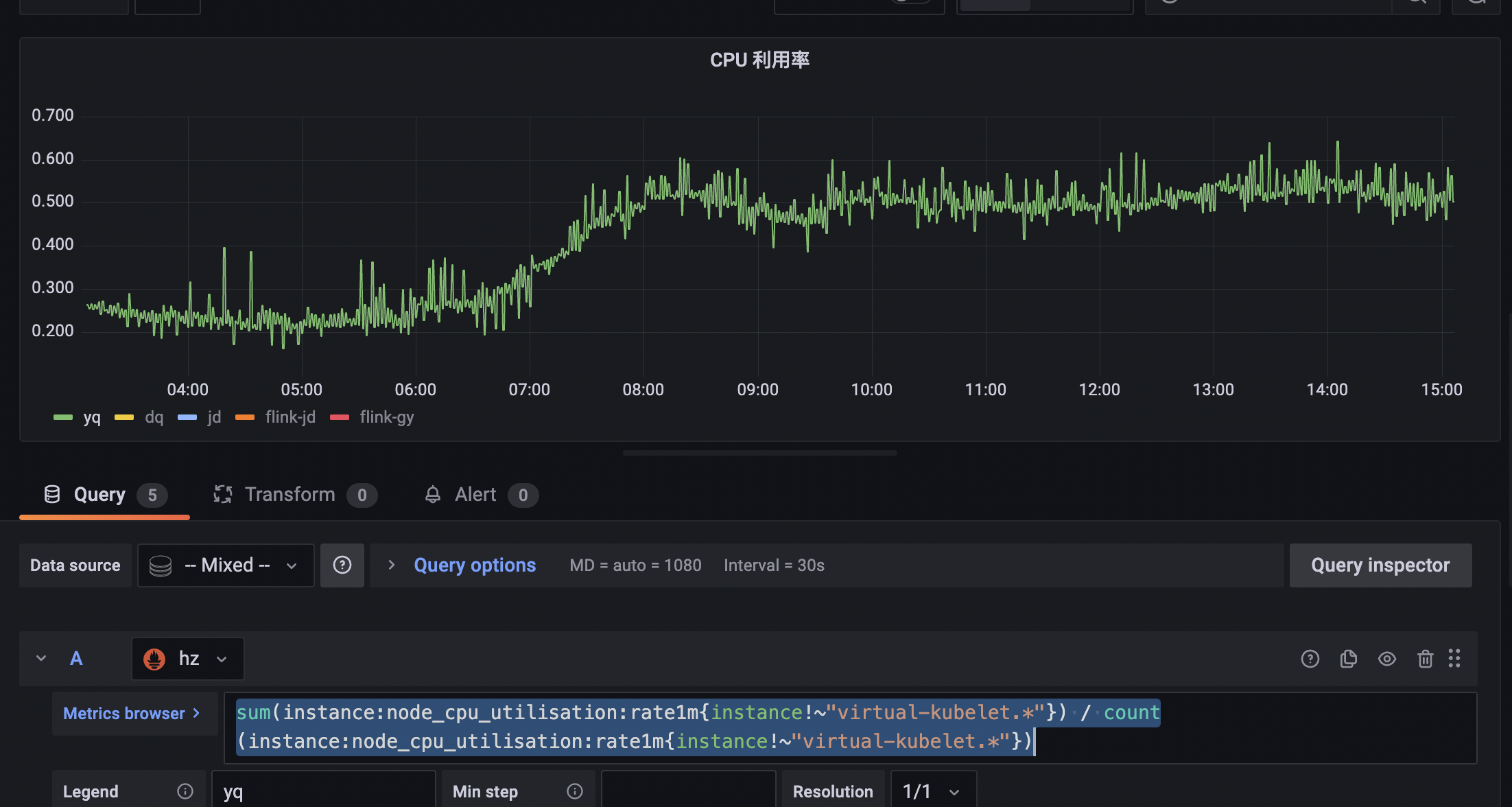
含义:查出每个节点上的单核平均利用率,做平均得到整个K8s集群的单核平均使用率
instance:node_cpu_utilisation:rate1m
- expr: |-
1 - avg without (cpu, mode) (
rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m])
)
record: instance:node_cpu_utilisation:rate1m含义:每个节点上的单核平均利用率(最近1分钟的rate)
node_cpu_seconds_total
含义:用于度量节点 CPU 使用情况。这个指标提供了 CPU 在不同模式下的使用时间,以秒为单位。
这个指标是一个 Counter 类型的指标,这意味着它的值只会增加(除非在系统重启时重置)。你可以通过计算这个指标在一段时间内的增量来度量 CPU 的使用率。
node_cpu_seconds_total{container="node-exporter",cpu="0",endpoint="metrics",instance="10.239.83.75:9100",job="node-exporter",mode="idle",namespace="monitoring",pod="kube-prometheus-prometheus-node-exporter-8775m",service="kube-prometheus-prometheus-node-exporter"} - cpu:每个核心的标号对应一个取值。如10.239.83.75这台机器是96核机器,那么cpu就有0~95个取值
- mode:cpu 运行模式
idle: CPU 处于空闲状态的时间。user: 用户级别应用程序的 CPU 使用时间。这包括大部分应用程序和进程。system: 内核级别应用程序的 CPU 使用时间。这包括处理系统调用和内核任务的时间。iowait: CPU 等待 I/O 操作完成的时间。nice: 改变优先级的用户级别应用程序的 CPU 使用时间。irq: 处理硬件中断的 CPU 使用时间。softirq: 处理软件中断的 CPU 使用时间。steal: 在虚拟环境中,等待虚拟 CPU 而被其他虚拟机占用的时间。
综上,节点上单核平均利用率计算分成3步:
- 计算节点上 每个CPU核心的 idle mode 最近一分钟内的平均cpu使用
rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m]- 计算节点维度,所有核心的平均 idle mode 使用
avg without (cpu, mode) (
rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m])
)- 计算节点维度,所有核心的平均实际使用
1 - avg without (cpu, mode) (
rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m])
)Rate、IRate、Increase
如下图:假设现在是9点30分,我们每隔 5s 采样一次,在 09:30:23 查询最近 20s 的 rate 和 irate 值,也就是 [3s, 23s] 的区间内增长了多少?这里的问题在于查询区间的时间与采样时间不重合
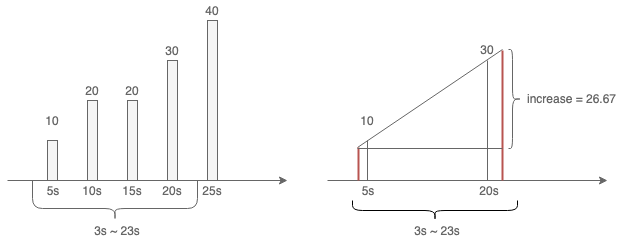
Rate
取 20s 内最近和最远的两个采样点: {5s: 10} 、{20s: 30},并计算它们的区间为 20 - 5 = 15s,期间请求量增长了 30 - 10 = 20 次。因此 rate(xxx[20s]) = 20 / 15 = 1.3333333
问题:Promtheus 如何解决exporter重启导致Counter值被重置?(counter下降,就认为是一种重置)
例如60秒内有下面6数值,在第四个数字后面发生了重置
2 4 6 8 2 4相关代码如下:
var (
counterCorrection float64 // 修正值
lastValue float64 // 最后一个值
)
for _, sample := range samples.Points {
// 每次出现counter值重置的情况,修正值就加上重置前的值
if isCounter && sample.V < lastValue {
counterCorrection += lastValue
}
lastValue = sample.V // 更新最后一个值
}
// 最后一个值 - 第一个值 + 修正值
resultValue := lastValue - samples.Points[0].V + counterCorrection2小于lastValue 8,所以 counterCorrection = 8
最后的 resultValue = 4 - 2 + 8 = 10,当然,重置的情况很少,这里如果不重置数据,假设Counter线性增长, [ 2 4 6 8 10 12 ],就是最后一个值减去第一个值resultValue = 12 - 2 + 0 和 重置算得一样
IRate
取 20s 内最近的两个采样点:{15s: 20} 、{20s: 30},并计算它们的区间为 20 - 15 = 5s,期间请求量增长了 30 - 20 = 10 次。因此 irate(xxx[20s]) = 10 / 5 = 2
Increase
做线性外插(等比延伸),如上图右侧展示,会计算出rate值后乘上increase的时间区间
Increase = rate * 20 = 20 / 15 * 20 = 26.67
这也解释了为什么int类型的Counter值,通过increase计算出来的值不是int
数据分析
查看 instance:node_cpu_utilisation:rate1m,也就是 1 - avg without (cpu, mode) (rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m]))
出现某些节点的值是负数的情况,且达到很大的值:0.5,会间歇性发生
可想而知,在这些节点的利用率有负数情况出现时,在计算平均节点单核利用率时,将大幅度拉低整体的值,导致出现断崖式下滑的情况
单独看某个节点 idle cpu 的rate 1m的值,有某些核心的值 > 1的情况
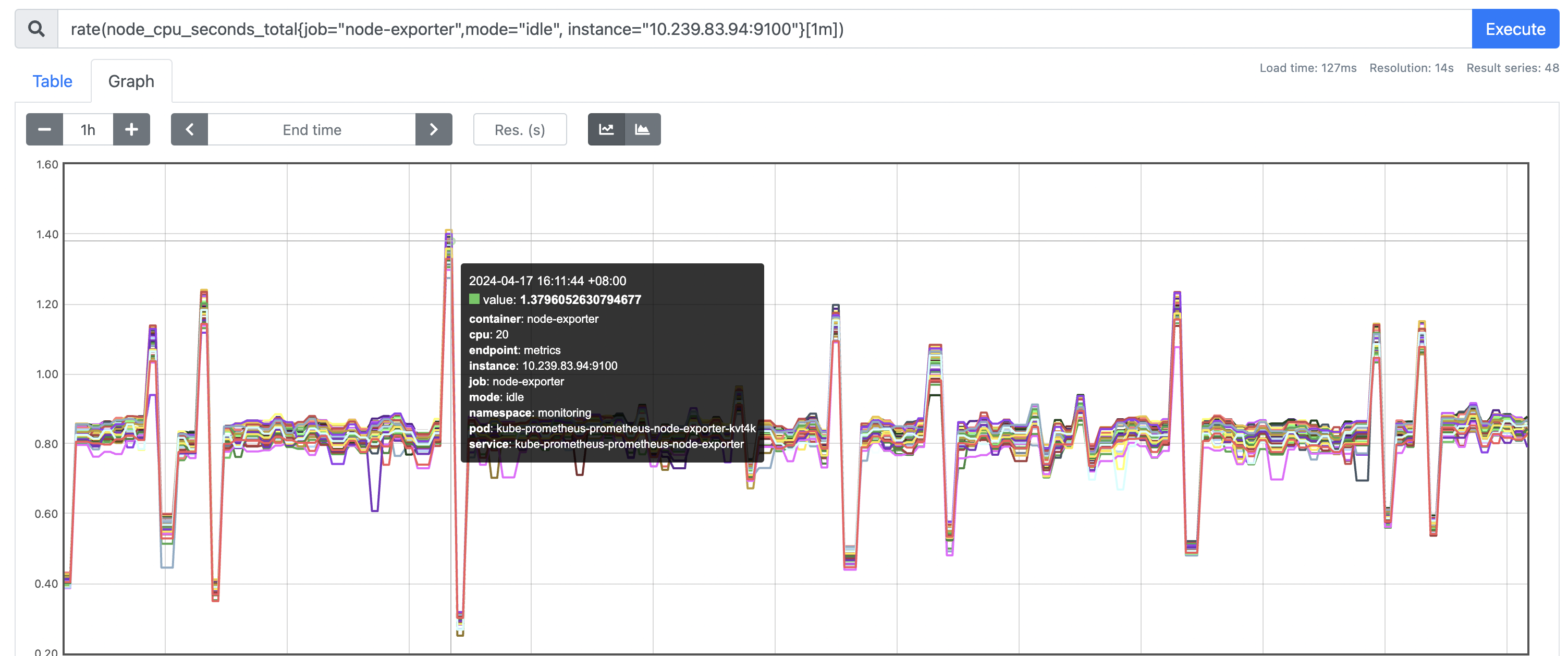
为什么 rate idle 会大于1 ?
猜想
问题要么出在Node-exporter,要么出在Prometheus
排查 Node-exporter
- 尝试 将 Node-Exporter(daemonset服务,挂载主机/proc目录,获取监控信息)升级到最新版本 —— 未能解决问题
- 尝试编写Client 每隔30s 拉取一次Node-Exporter指标,看相邻的两次样本值的差值
日志打印如下,一共运行了20min,只有一次样本差值 30.019999995827675 微微超过30,考虑到样本值的类型是一个float,并且定时任务也无法保证间隔是精确的30s,所以这次可以认为在误差允许范围内
基本可以判断 Node-exporter的逻辑没有问题
2024-04-19 16:11:35.723807 +0800 CST m=+60.001623334
Gap: 29.849999994039536
2024-04-19 16:12:05.724161 +0800 CST m=+90.002162126
Gap: 29.87000000476837
2024-04-19 16:12:35.723935 +0800 CST m=+120.002120709
Gap: 29.53999999910593
2024-04-19 16:13:05.722918 +0800 CST m=+150.001288043
Gap: 27.87999999523163
2024-04-19 16:13:35.738429 +0800 CST m=+180.016983334
Gap: 29.890000000596046
2024-04-19 16:14:05.754946 +0800 CST m=+210.013578418
Gap: 29.87000000476837
2024-04-19 16:14:35.752635 +0800 CST m=+240.002515584
Gap: 30.019999995827675
2024-04-19 16:15:05.753538 +0800 CST m=+270.002130959
Gap: 29.80000000447035
...排查 Prometheus
- 可能和负载压力有关系。Prometheus cpu使用达到 15.5核心,出现 23.4%的被限流的情况(30,000+的协程处理各项任务(指标拉取、聚合rule计算、告警规则计算、服务发现、配置热加载等等)
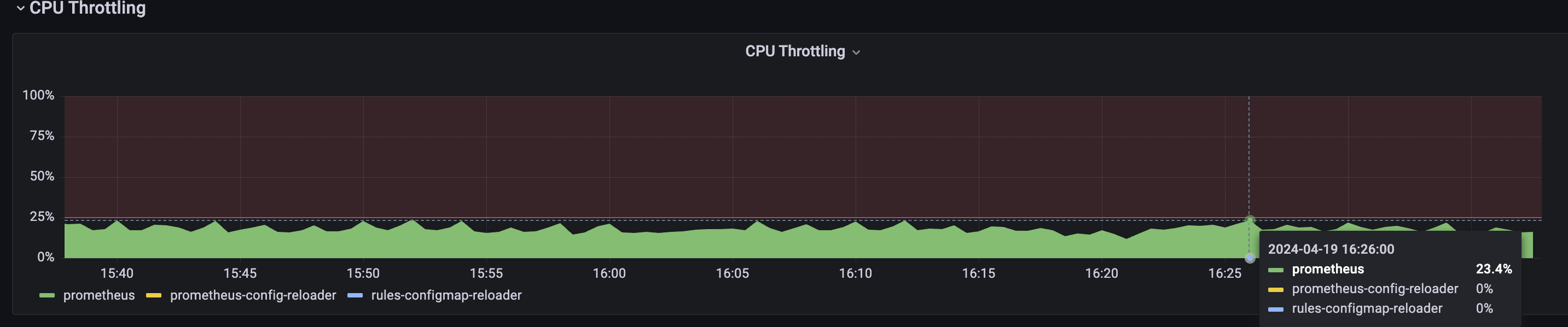
观测:
基于上述的 rate 计算逻辑,我们先取出 Prometheus 原始采集的样本数据,选择某个idle rate > 1的时间点,找最近1分钟的采样点,一共有2个(30s的采集周期,符合预期):

- 采样1: 88647709.3 @1713341448.972
- 采样2: 88647751.24 @1713341479.372
样本值差值:88647751.24 - 88647709.3 = 41.94
时间戳差值:1713341479.372 - 1713341448.972 = 30.4000001
rate = 41.94 / 30.4000001 = 1.37960526 > 1
与Prometheus 界面上通过Rate函数计算出的一致,验证了Rate计算的逻辑
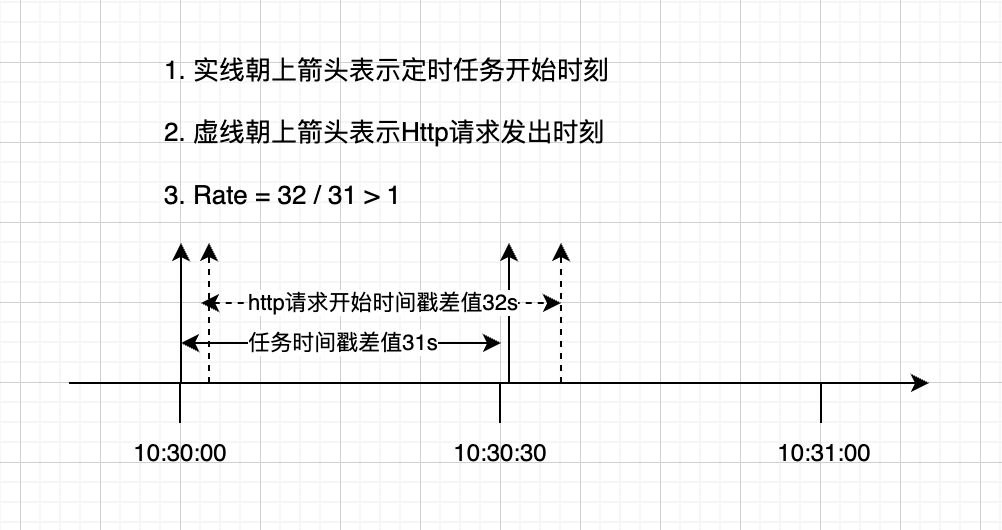
取其他时刻点,发现时间戳的值普遍 > 30s,有的达到31s、32s,明明配置了30s的采集间隔,为什么会有这种差异?
为什么时间戳差值 > 30s?
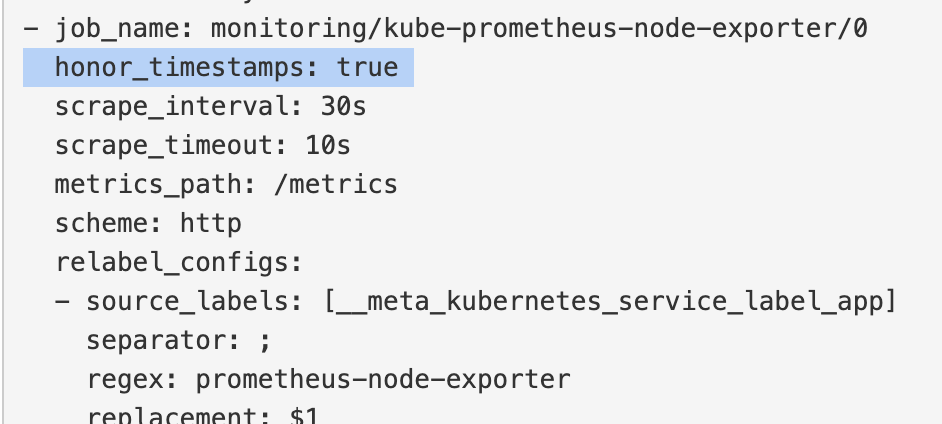
Node-exporter 采集任务配置了 尊重指标来源设置的时间戳(Prometheus 默认采用此配置),但从指标接口拉取的指标里不包含时间戳,所以最终会使用Prometheus自身的时间戳,作为指标最终的时间戳
包含时间戳的指标返回格式样例:
container_health_check_duration_millisecond{container_name="prometheus-node-exporter",namespace="monitoring",pod_name="kube-prometheus-prometheus-node-exporter-znxsv"} 2.3509091e+07 1713756155090 - 样本名:container_health_check_duration_millisecond (内在实现上,存储为 “ __name_"_ = “container_health_check_duration_millisecond” 的标签对)
- 样本标签对:{container_name=”prometheus-node-exporter”,namespace=”monitoring”,pod_name=”kube-prometheus-prometheus-node-exporter-znxsv”}
- 样本值:2.3509091e+07
- 样本时间戳:1713756155090 -> 由客户端实现决定,node-exporter没有实现这一逻辑(绝大多数Exporter,都没有这样实现,原因待分析),接口返回里就没有这个字段
// 客户端调用此方法可以给指标带上时间戳
ch <- prometheus.NewMetricWithTimestamp(time.Now(), metric)Prometheus指标时间戳设置流程
Target:指一个拉取指标的目标地址,如 http://1.2.3.4:8080/metrics
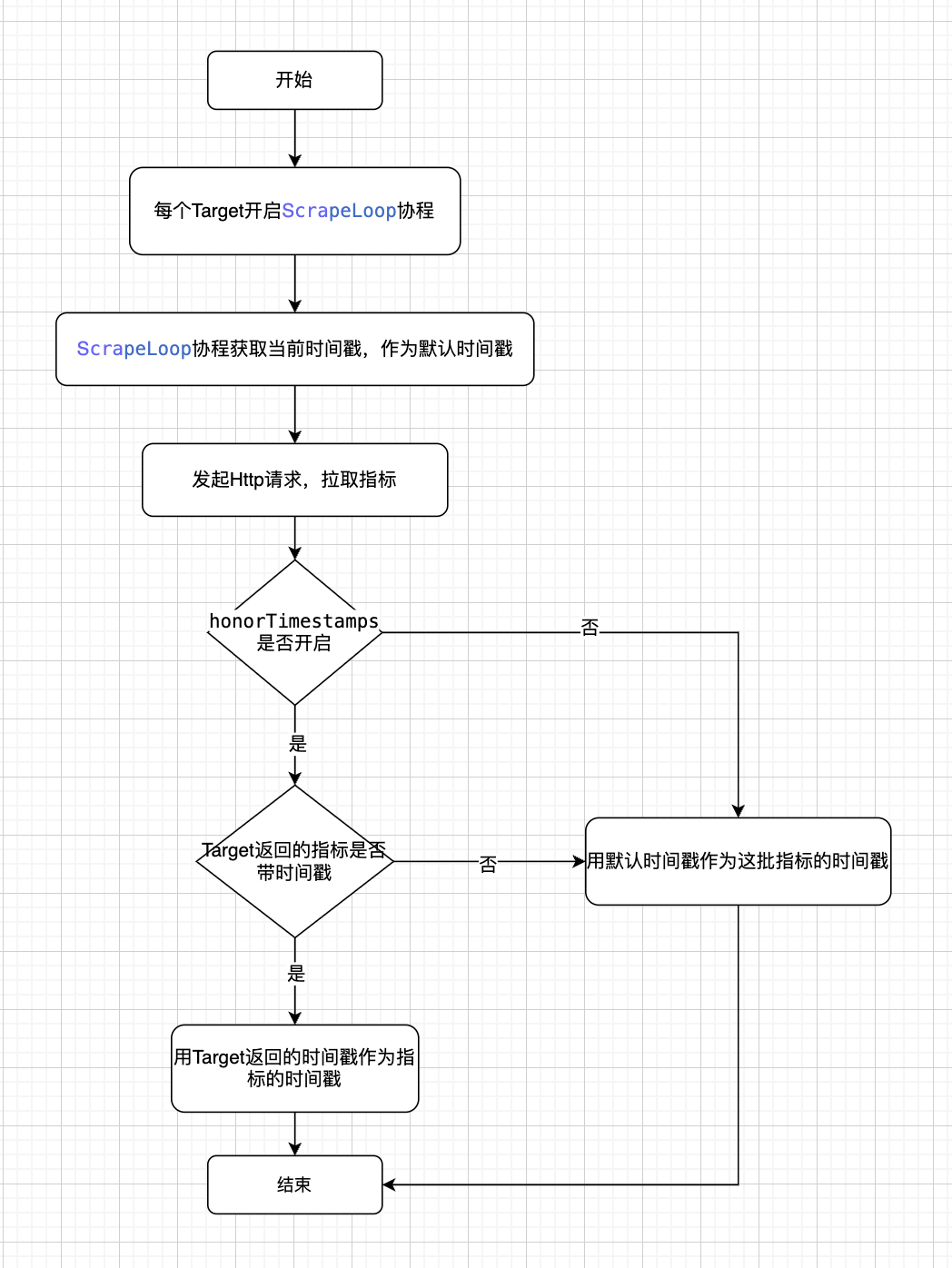
分析:
Prometheus每个副本启动了30,000+的协程处理各项任务(指标拉取、聚合rule计算、告警规则计算、服务发现、配置热加载等等)协程间的切换频繁,会导致:
- 30s一次的 时间间隔 无法得到保证,如上面的例子里就达到了 30.4000001s
- 定时任务触发后,在Http请求发出前,可能因协程切换,导致请求未得到有效处理,即实际等待了一段时间,才发出请求。因 协程间的切换的不确定性,有可能前一次拉取没有上面这种情况,但第二次拉取出现了,最终会导致两次Count的值的差值偏大,超过了两次拉取的时间差值,就会导致最终相除 > 1
示意图如下,在10:31:00,计算rate 1m的值,区间内有两个点:
验证负载压力的影响:
在测试环境的 Prometheus中(负载压力很低),配置静态拉取,选一台节点作为目标
果然,差异出现了。测试环境的Rate计算始终不会超过1
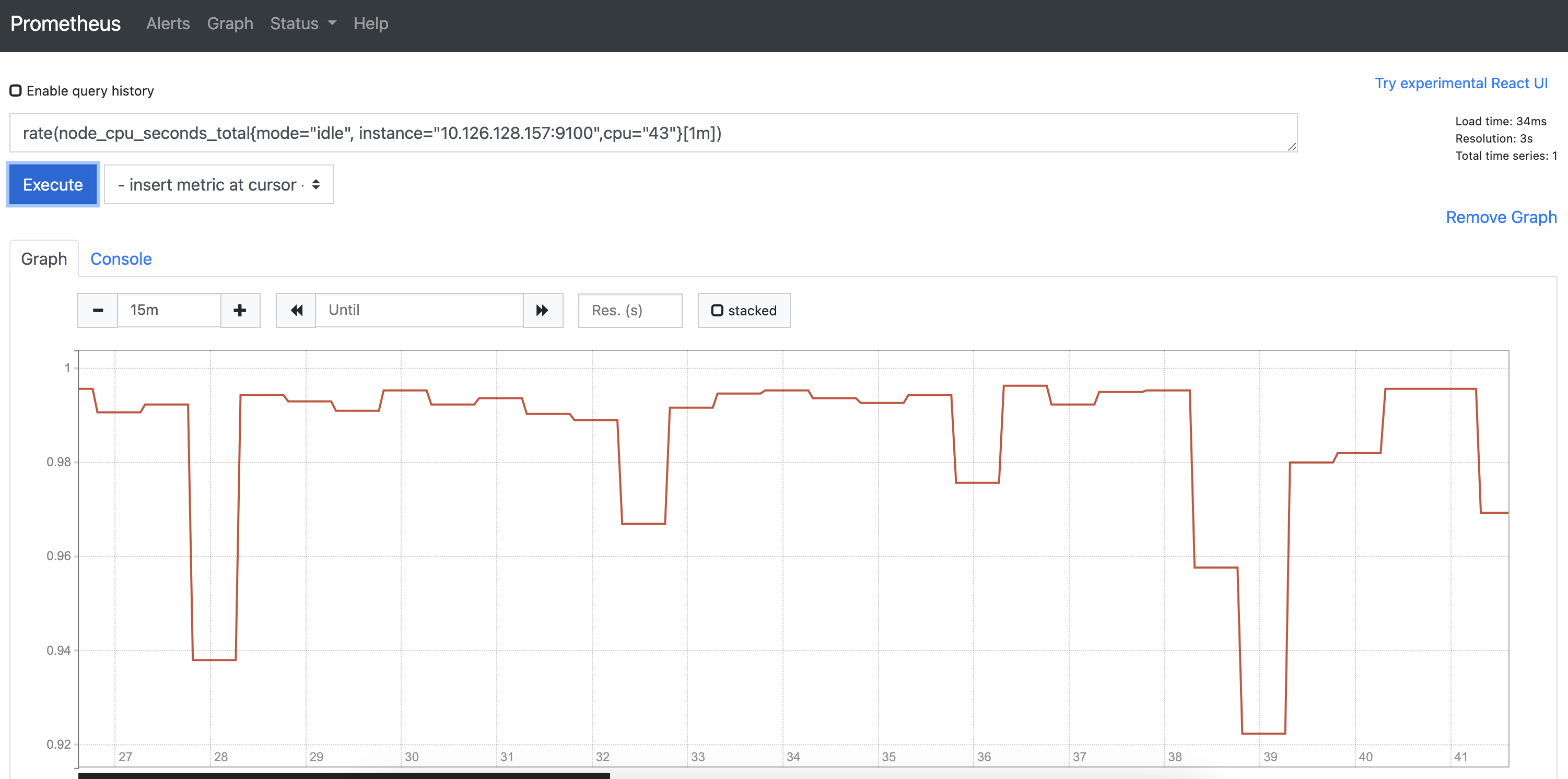
可以实锤和 Prometheus 的负载压力有关
改进措施
措施1:去掉 CPU limit
作用:解决Prometheus限流问题 —— 去掉 CPU limit
效果:最近一天的单核心平均CPU利用率
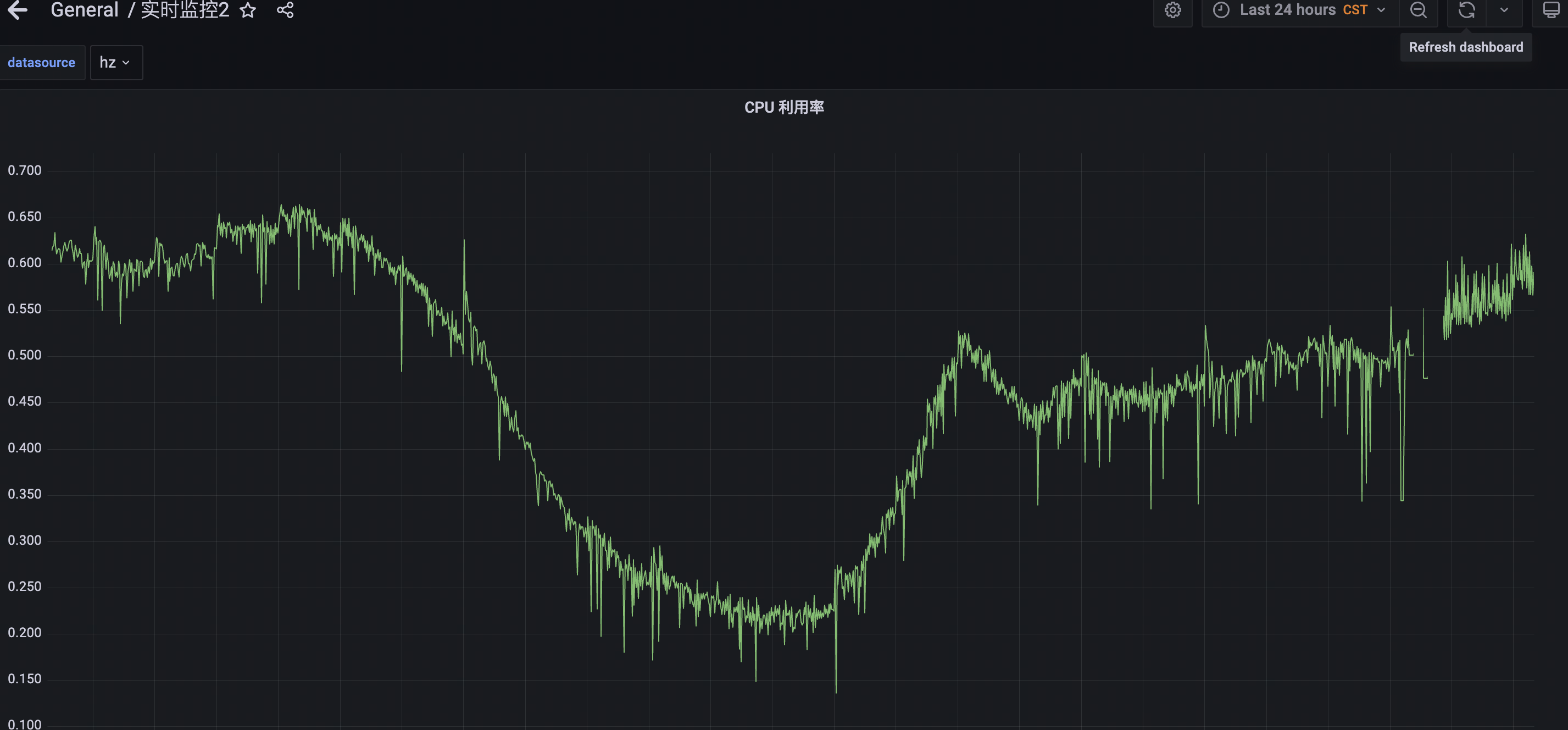
总结:
- 一下子下落很多的情况基本消失了
- 整体上下波动还是比较大
措施2:调大Rate时间区间
作用:减轻Prometheus负载高导致的协程任务无法及时处理的影响
首先看下社区最新是如何统计节点利用率的
prometheus-community 社区实践(我们的Prometheus Chart基于他们的3年前的版本)
- expr: |-
1 - avg without (cpu) (
sum without (mode) (rate(node_cpu_seconds_total{job="node-exporter", mode=~"idle|iowait|steal"}[5m]))
)
record: instance:node_cpu_utilisation:rate5m两处差异:
- 不仅仅将idle,还将iowait和steal的cpu使用反选
- rate 时间为5m
另一处社区实践:
https://monitoring.mixins.dev/node-exporter/
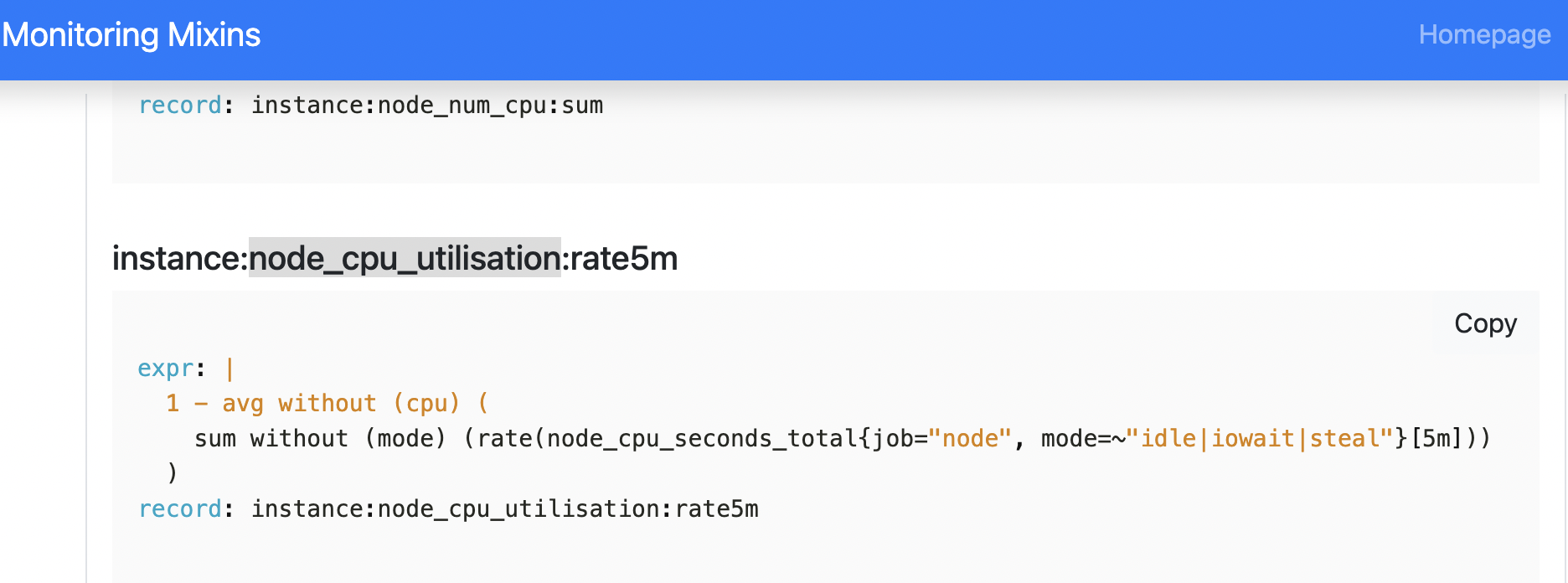
和 prometheus-community 社区的实践一致
我们当前使用的Rate时间区间是1m,和拉取间隔30s是不匹配的。建议 Rate的区间至少设置为拉取间隔的4倍,在如下文章里有提到:
“建议将rate计算的范围向量的时间至少设为抓取间隔的四倍。这将确保即使抓取速度缓慢,且发生了一次抓取故障,您也始终可以使用两个样本。此类问题在实践中经常出现,因此保持这种弹性非常重要。例如,对于1分钟的抓取间隔,您可以使用4分钟的rate 计算,但是通常将其四舍五入为5分钟。”
将rate的时间区间调整为5m,再次查询。节点cpu利用率出现负数的情况大大减少,值也很小,几乎消失了
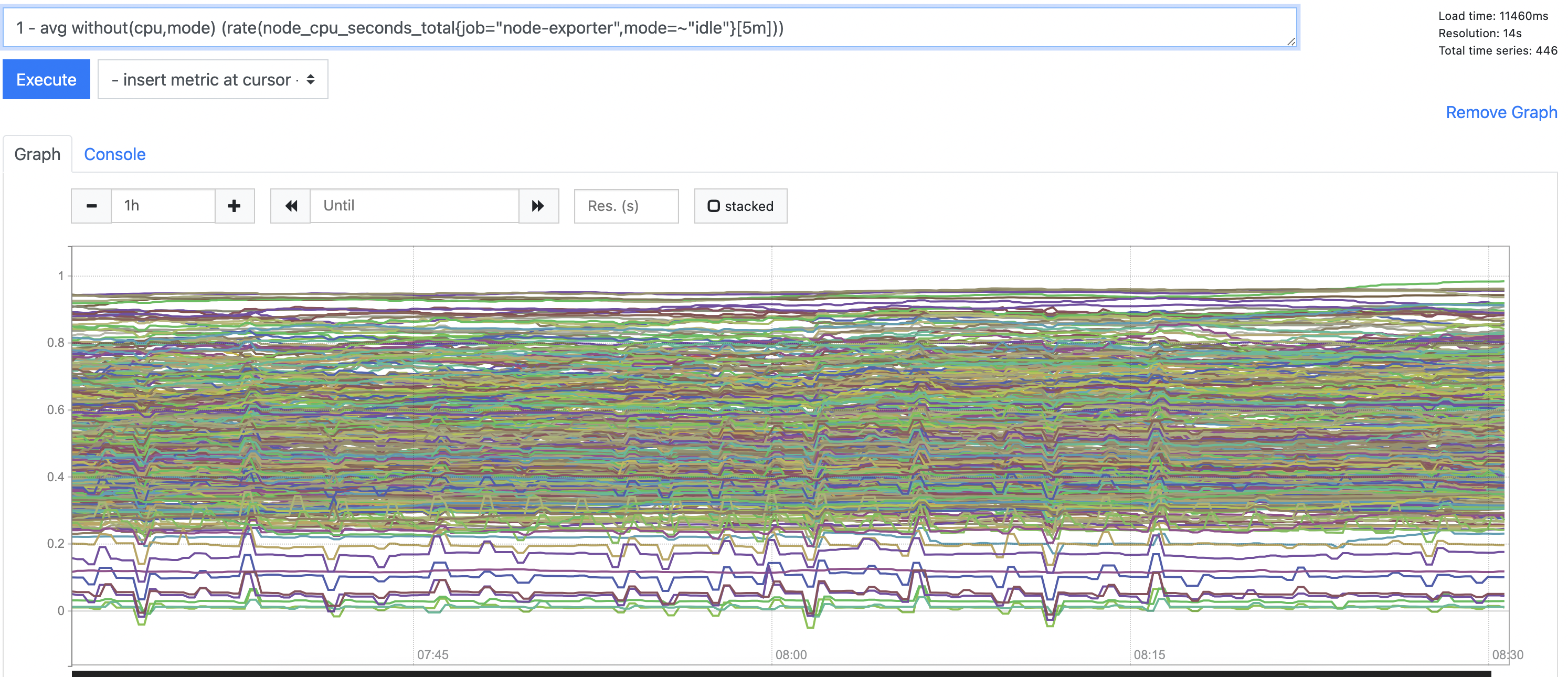
总结:
当把rate区间从1m调整为5m,虽无法彻底规避协程切换带来的影响 —— 相邻拉取任务 指标值的差异不对应时间戳的差异,但在更长时间范围内进行统计,这种差异可以缩小,尤其在计算比例时。
rate = 指标值差异 / 时间戳差异
覆盖的采集点从 2个 -> 10个,有的相邻采样点的差异趋于一致,会使得整体差异变小
另外,rate 5m也可以使得整体利用率曲线更加平稳,不会出现短时间内一直来回波动的情况
文档参考
- 为什么 Prometheus increase 不返回整数?
- prometheus的rate与irate内部是如何计算的
- Promethues 如何设计 Counter Prometheus团队在KubeCon的分享,非常经典,推荐观看
- 高可用prometheus:常见问题 作者做了大量的调研工作,解决了监控领域大量的困惑,推荐阅读
- Reliable Insights — A blog on monitoring, scale and operational Sanity Prometheus核心开发者的博客,很多干货